AI孙燕姿全网沸腾!AI翻唱大爆发,整个华语乐坛都"复兴"了
来源:墨迹说体育 人气:35843 更新:2023-05-08 20:54:39
编辑:桃子 好困
【新智元导读】最近,一位「冷门歌手」竟靠着AI替身,翻唱华语乐坛歌曲爆红全网。
一夜之间,「AI孙燕姿」火遍全网。
B站上,AI孙燕姿翻唱的林俊杰「她说」、周董「爱在西元前」、赵雷「成都」等等,让一众网友深陷无法自拔。
「冷门歌手」孙燕姿新晋成为2023年度热门歌手,掀起许多人的追星狂欢。
网友表示,「听了一晚上AI孙燕姿,出不去了......」

这些翻唱歌曲,是由Eternity丨L、罗斯特_x等UP主通过开源项目自制后并上传。
(作者似乎特意在「半岛铁盒」中加入了一秒空白,凑成5分20秒)
UP主:Eternity丨L
除了AI孙燕姿,还有AI周杰伦,AI王心凌、AI林志炫...

可能许多人做梦也没有想到,2023年华语乐坛竟以这种形式复兴了。
「AI孙燕姿」在线营业
前段时间,一位TikTok网友用AI创作了一首「Heart on My Sleeve」很快蹿红网络,引来1000多万人围观。
听完这首歌的网友纷纷表示,太让我惊讶了,简直太疯狂!
这首歌正是用两位美国流行音乐人Drake和The Weeknd的声音创作而成。先通歌手声音训练AI,然后再用AI来创作。

在国内,B站上AI翻唱的华语乐坛歌曲也渐渐成为许多人关注的焦点,孙燕姿、王心凌、周杰伦等明星纷纷「复出」。
而最火的莫过于孙燕姿,凭借「天后音色」的称号,直接成为AI新宠儿。
UP主:罗斯特_x
有人还自制了AI孙燕姿粤语版《爱来的太迟》。
然而,对于AI音乐制作,在整个音乐行业并非是一个新事物了。只不过生成式AI的大火,让AI翻唱的门槛再次被拉低。
比如,年初,谷歌还曾推出了文本到音乐模型MusicLM,通过将音乐的生成过程视为分层的序列到序列建模任务,并以24 kHz的频率生成高保真的音乐。

对于许多歌迷来讲,AI翻唱一定程度上满足了自己的许多遐想。
还有一些歌迷,自己训练了已故经典老歌手的AI,包括阿桑、张国荣、姚贝娜、邓丽君等等。
这或许是一种数字永生,通过这样一种方式让久违的声音再次回到人们心里。

Midjourney出图逼真的超强能力,让人们惊呼画家要失业了。对于AI翻唱,难道歌手也要被去取代吗?
一位UP主@阿张Rayzhang用自己的音色训练出的AI唱Killer Queen后,瞬间感觉太恐怖了。
紧急录制一个视频后,并附上了「AI歌手会让翻唱区集体失业吗?我被AI版的我爆杀!」标题。
有网友称,自己就是AI第一批受害者画手,感觉什么职业也逃不掉。

有些人也表示,翻唱的有些地方一点也不像。
要知道,对于AI翻唱来讲,也需要丰富的特定艺术家音色训练数据,这样AI生成的作品才更加真实。
就目前的技术,虽然歌手的唱腔、技巧和风格等还不能完全模仿,但音色已经基本能完全复刻。
但是真正的大家是不能被取代。

AI翻唱火虽火,但由AI创作音乐的另一面,是迫在眉睫的版权问题。
AI创作的「Heart on My Sleeve」在TikTok上风靡一时后,完整版被上传到了Apple Music、Spotify、YouTube等平台上。
就此,美国歌手Drake对此在Ins表达了不满,「这是(压死骆驼的)最后一根稻草了」。目前,这首歌因为侵权问题已经下架。
《金融时报》称,拥有Taylor Swift、Bob Dylan等巨星版权的环球音乐集团,正敦促Spotify和苹果阻止AI工具从其艺术家的版权歌曲中抓取歌词和旋律。
但是有些艺术家却不吝啬自己的声音,马斯克前女友Grimes在网上表示,
「任何人都可以使用我的声音AI生成歌曲。」不过,还得再付50%的版权。

而这次大火的AI翻唱背后的原始项目「so-vits-svc」的作者,据称也是因为太多人滥用,而删除了项目。
SoVitsSvc:唱歌声音转换

歌声转换模型使用SoftVC内容编码器来提取源音频语音特征,然后将向量直接送入VITS,而不是转换为基于文本的中间格式。因此,音高和音调都可以被保留下来。
此外,项目开发者还通过采用NSF HiFiGAN作为声码器(vocoder),从而解决了声音中断的问题。

· 特征输入改为Content Vec · 采样率统一使用44100Hz
· 由于参数的改变,以及模型结构的精简,推理所需的GPU显存明显减少。
· 增加选项1:vc模式的自动音高预测,这意味着在转换语音时不需要手动输入音高键,男声和女声的音高可以自动转换。但是,这种模式在转换歌曲时,会造成音高偏移。
· 增加选项2:通过k-means聚类方案减少音色泄漏,使音色与目标音色更相似。
· 增加选项3:增加NSF-HIFIGAN增强器,对一些训练集少的模型有一定的音质增强效果,但对训练好的模型有负面影响,所以默认关闭。
预训练模型文件
将checkpoint_best_legacy_500.pt放在hubert目录下。
将G_0.pth和D_0.pth放在logs/44k目录下。
预处理
0. 音频切片
利用audio-slicer-GUI或audio-slicer-CLI工具,将原始音频切片至5秒-15秒。
长一点也没问题,但太长(比如30秒)可能会在训练甚至预处理时导致「torch.cuda.OutOfMemoryError」,俗称爆显存。
切片后,删除过长和过短的音频。
1. 重采样至44100Hz和单声道
python resample.py
2. 自动将数据集分成训练集和验证集,并生成配置文件
python preprocess_flist_config.py
3. 生成hubert和f0
python preprocess_hubert_f0.py
完成上述步骤后,dataset目录将包含预处理的数据,dataset_raw文件夹可以被删除。
现在,你可以修改生成的config.json中的一些参数——
keep_ckpts:在训练中保留最后的keep_ckpts模型。设置为0将保留所有模型,默认是3。
all_in_mem:将所有数据集加载到RAM中。当某些平台的磁盘IO太低,而系统内存比你的数据集大得多时,可以启用。
训练
python train.py -c configs/config.json -m 44k
推理
模型在需要使用「inference_main.py」。
举个例子:
python inference_main.py -m "logs/44k/G_30400.pth" -c "configs/config.json" -s "nen" -n "君の知らない物語-src.wav" -t 0
虽然原始项目组现已停止维护,但有不少网友都进行了fork并且也做了一些更新。
比如下面这个图形化界面:
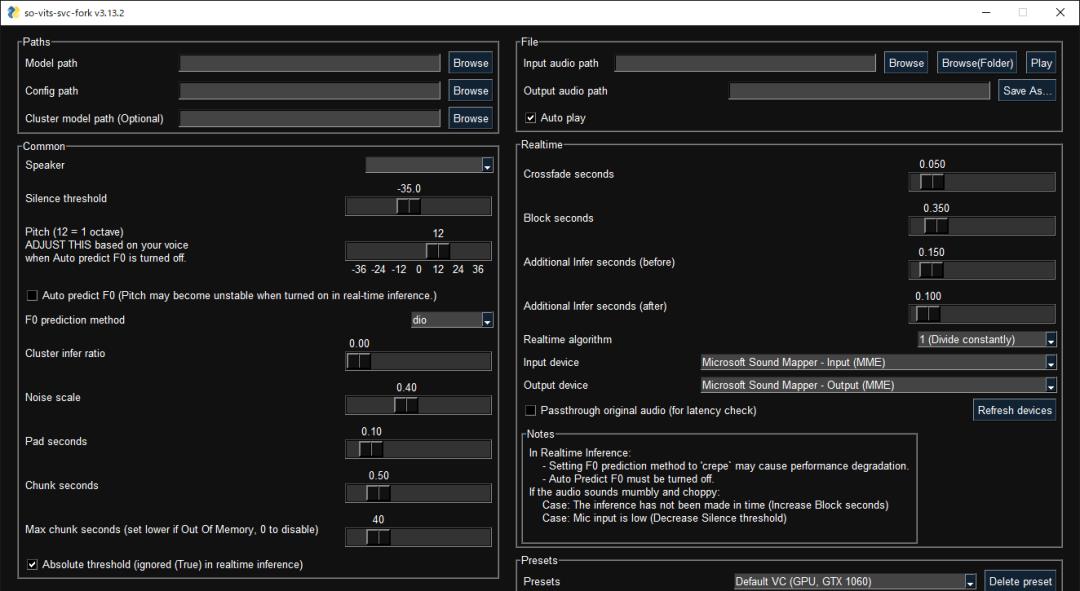
AI「复活」
AI翻唱之外,许多网友此前曾做了类似的项目,比如「AI-Talk」让马斯克和乔布斯进行了穿越时空的对话。
视频中,AI不但模拟了他们的声音,还在一定程度上模拟了其对话思路,使得交流过程十分流畅。
AI让我们与逝者的对话成为可能。此前,B站UP主用AI还复活了老奶奶。
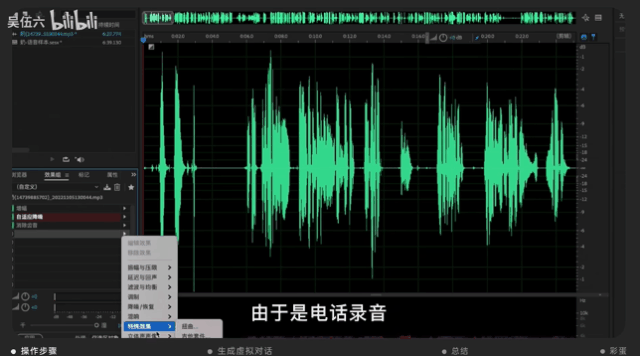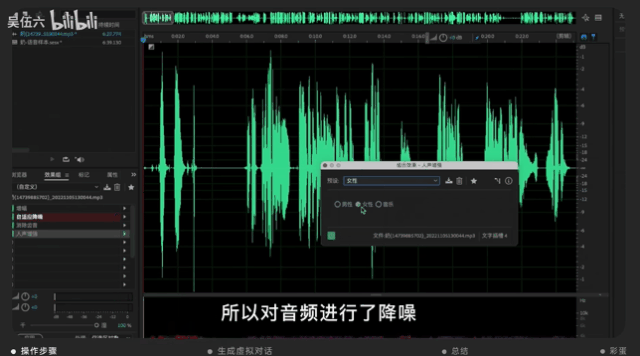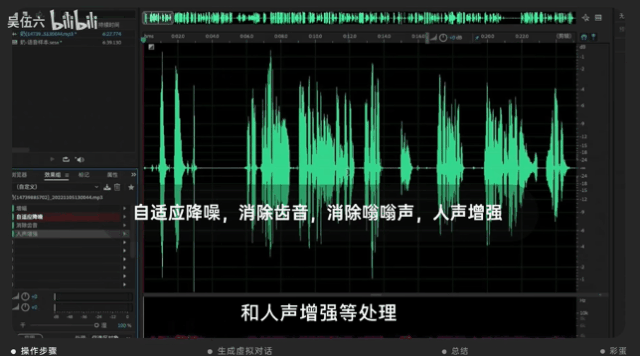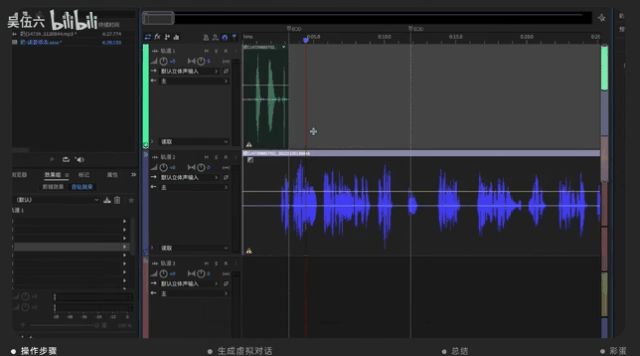
对于老奶奶的声音制作,直接把过去已有的音频上传,素材基本来自于过去的电话录音、录像视频或者微信语音。
并用音频编辑软件AU进行调整,调整的方向主要在降噪、人声增强等等。
然后将更加清晰的音频样本切割成若干秒的短句,方便进行标注。最后将处理好的音频打包放入语音合成系统中去。
利用语音合成系统,就可以尝试输入文本转语音了。
网友见证科技狠活
AI孙燕姿的歌,已经唱到许多网友的心坎。

最近沉迷AI「翻唱」,上至AI侃爷唱罚酒,下至苏小玎唱真相是真。但说句正经的,确实还是AI届顶流孙燕姿的翻唱最好听。

这几天沉迷B站的AI孙燕姿,刚刚听了一首《一场游戏一场梦》,太好听了,唱到心坎里

不少网友听过AI翻唱的歌曲后,感受到AI歌手的可怕之处:
科技的力量真是让人细思极恐。

深深感受到了什么叫做科技的力量......

这就是AI生命,数字飞升!

还有网友对逝去歌手的怀念。

参考资料:
热门资讯
- 悲痛!网红“涛哥”去世,死因曝光获百辆豪车送殡,赵本...
- 善恶终有报,这一次张译的话终于应验了,将“众星”底裤...
- 景甜新浪大楼亮相,圆脸大眼睛“富贵花十足”,生图也白...
- 无知还是有意为之?霍尊直播唱禁歌!
- “偶练”毕雯珺、“创1”李子璇,那些错过成团的练习生还好...
- 王俊凯,刘雨昕,王鹤棣,王子异,任泉
- 68岁张国立疑定居法国!紧抱娇妻现身高档餐厅,生活质...
- 《奔跑吧9》再次迎来家属助阵,郑恺老婆加盟,全员整蛊...
- 张雨绮:这个情路悲苦的女人,终于“解脱”了
- 王思聪又结新欢?与才17岁的姚心怡去米其林,一身穿搭...
- 曾志伟重返TVB连升三级,荣升行政委员会成员,与高层同...
- 何炅谢娜再合体乘风姐姐与好6团合跳《你好,星期六》主...
- 《法证先锋5》宣传活动买粉丝造势?TVB:不是事实
- Angelebaby翻译成中文是什么?Baby在跑男上就已给出了...
- 无视节目组规则,《极挑》后期人员这一手操作,在打导...
- 中国好声音:两轮战队赛之后,哪些学员有望成为总决赛...
- 也评电影《满江红》:解锁“九连环”般故事背后的家国情怀
- 18年后再看袁茵,才看懂她当年为何会离开侯耀文,转身...
- 王俊凯与天王同台,粉丝:这是要开启宇宙级演唱会吗?
- 又一部生猛韩片诞生,被打出9.5分,轻松夺下票房冠军!